- 内部数据结构
- 内存映射数据结构
- Redis数据类型
- 功能的实现
- 内部运作机制
1、内部数据结构
1.1 简单动态字符串
1.1.1 sds的用途
sds(Simple Dynamic String)简单动态字符串- Redis底层所使用的的字符串表示
- 用途
- 实现字符串对象
- 用作
char*类型替代品
1.1.2 Redis中的字符串
sds的实现1 2 3 4 5 6 7typedef char *sds struct sdshdr { int len; // buf已占用长度 int free; // bug剩余可用长度 char buf[]; //实际保存字符串数据的地方 }
1.1.3 优化追加操作
- 如果free空间足够,无须再分配空间。如果不够计算新字符串的总长度。
- 如果追加字符串小于
1M,分配多余所需空间一倍(新字符串长度1倍)的空间。否则,额外多分配1MB。
1.1.4 sds模块的API

1.1.5小结
- Redis的字符串表示为
sds,而不是C字符串(以\0结尾的char*) - 对比C字符串,
sds有以下特性- 可以高效计算长度
- 可以高效执行追加操作
- 二进制安全
sds为追加操作进行优化:加快追加操作速度,并降低内存分配的次数。代价是多占用内存,并且这些内存不会被主动释放
1.2 双端链表
1.2.1 双端链表的应用
- 实现Redis的列表类型
- Redis列表使用两种数据结构作为底层实现
- 双端链表
- 压缩列表
- 创建新的列表键时,优先考虑使用压缩列表,在有需要的时候在转换为双端链表
- Redis列表使用两种数据结构作为底层实现
- Redis自身功能的构建
- 事务模块保存命令
- 服务器模块保存多个客户端
- 订阅/发送模块保存订阅模式的多个客户端
- 事件模块保存时间事件
- 。。。
1.2.2 双端链表的实现
双端链表的实现由listNode和list两个数据结构构成
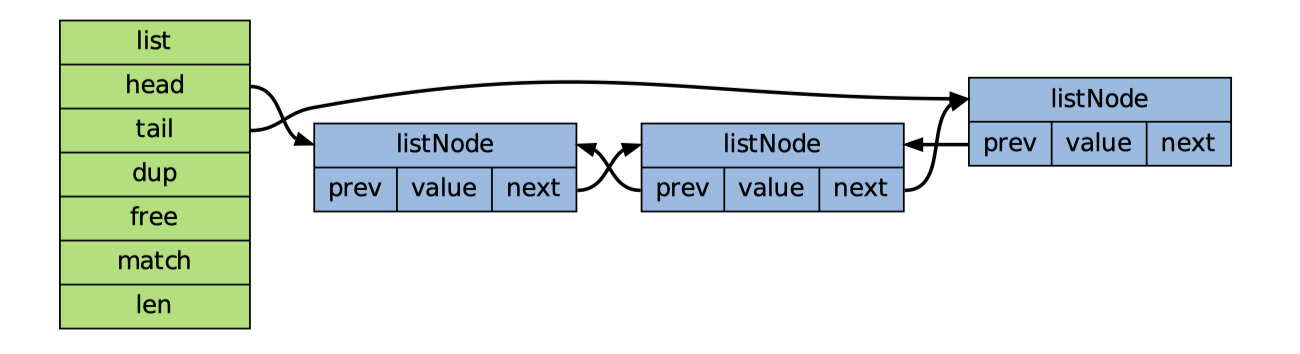
listNode是双端链表的节点
1 2 3 4 5typedef struct listNode{ struct listNode *prev; // 前驱结点 struct listNode *next; // 后继节点 void *value; // 值 } listNode;value的属性是void *,说明对保存的值的类型不做限制
list是双端链表本身
1 2 3 4 5 6 7 8typedef struct list{ listNode *head; //表头指针 listNode *tail; //表尾指针 unsigned long len; // 节点数量 void *(*dup)(void *ptr); // 复制函数 void (*free)(void *ptr); // 释放函数 int (*match)(void *ptr, void *key); // 比对函数 } list;
双端链表API

1.2.3 迭代器
Redis为双端链表实现了一个迭代器,可以从两个方向进行迭代
- 沿着next指针从表头向表尾
- 沿着prev指针从表尾向表头
结构定义:
| |
- direction选项
adlist.h/AL_START_HEAD从表头到表尾adlist.h/AL_START_TAIL从表尾到表头
- 迭代器API
- 
1.2.4 小结
- Redis实现了自己的双端链表
- 双端链表的主要作用
- 列表类型的底层实现之一
- 作为通用数据结构,被其他功能模块使用
- 双端链表及其节点的性能特性
- 访问前驱结点和后继节点复杂度都是O(1),并且对链表的迭代可以从表头和表尾两个方式开始
- 对表头和表尾处理的复杂度为O(1)
- 计算链表长度复杂度O(1)
1.3 字典
1.3.1 字典的应用
字典应用广泛
- 实现数据库键空间
- 数据库中键值对由字典保存,每个数据库都有一个与之相对的字典,成为键空间
- 用作Hash类型键的一种底层实现
- Redis的Hash类型键使用两种数据结构作为底层实现
- 字典
- 压缩列表
- 创建新的
Hash键时,默认使用压缩列表作为底层实现,有需要再转换字典
- Redis的Hash类型键使用两种数据结构作为底层实现
1.3.2 字典的实现
实现方法有多种:
- 最简单,使用链表或数组,但是只适用于元素个数不多的情况
- 兼顾高效和简单,使用哈希表
- 最求稳定性并且希望高效地实现排序,可以使用平衡树
Redis选择了高效且简繁的哈希表作为字典的底层实现。
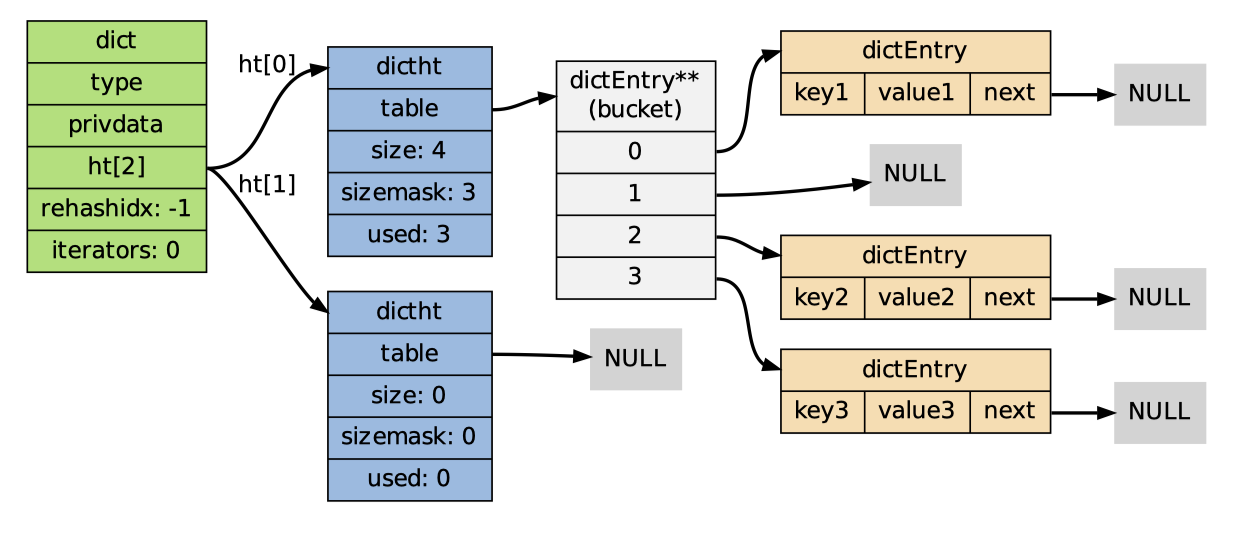
1 2 3 4 5 6 7typedef struct dict { dictType *type; // 特定于类型的处理函数 void *privdata; // 类型处理函数的私有数据 dictht ht[2]; // 哈希表(2个) int rehashidx; // 记录rehash进度的标志,值为-1表示rehash未进行 int iterators; // 当前正在运作的安全迭代器数量 } dict;dict的API

哈希表的实现
1 2 3 4 5 6 7// dict.h/dicht typedef struct dictht { dictEntry **table; // 哈希表节点指针数组(俗称桶,bucket) unsigned long size; // 指针数组的大小 unsigned long sizemask; // 指针数组的长度掩码,用于计算索引值 unsigned long used; // 哈希表现有的节点数量 } dictht;table属性是一个数组,数组每个元素都是一个指向dictEntry结构的指针。每个
dictEntry都保存着一个键值对,以及一个指向另一个dictEntry结构的指针:1 2 3 4 5 6 7 8 9typedef struct dictEntry { void *key; // 键 union { void *val; uint64_t u64; int64_t s64; } v; // 值 struct dictEntry *next; // 链往后继节点 }
整个字典结构:
哈希算法
Redis使用两种不同的哈希算法
MurmurHash2 32 bit 算法https://github.com/aappleby/smhasher- 基于djb算法实现的一个大小写无关散列算法 http://www.cse.yorku.ca/~oz/hash.html
使用哪种算法取决于具体应用所处理的数据:
- 命令表以及Lua脚本缓存使用算法2
- 数据库、集群、哈希键、阻塞操作等功能使用算法1
1.3.3 创建新字典
dict *d = dictCreate(&hash_type, NULL)
1.3.4 添加键值对到字典
添加流程:
- 如果字典未初始化(即字典的0号哈希表的table属性为空),那么程序需要对0号哈希表进行初始化
- 如果在插入时发生了键碰撞,那么程序需要处理碰撞
- 如果插入新元素使得字典满足
rehash条件,那么需要启动响应的rehash程序
1.3.5 添加新元素到空白字典
当第一次往空字典里添加键值对时,程序会根据dict.h/DICT_HT_INITIAL_SIZE里指定的大小为d->ht[0]->table分配空间(目前为值4)。
1.3.6 添加新键值对时发生碰撞处理
使用链地址法,将新的键值对链接到存在的键值对上。
1.3.7 添加新键值对时触发了rehash操作
对于使用
链地址法来解决碰撞问题的哈希表,性能依赖于它的大小(size属性)和它所保存的节点的数量(used属性)之间的比率:- 比率1:1,哈希表性能最好
- 如果节点数量比哈希表大小要大很多,哈希表就会退化成多个链表,性能优势不再存在
为了保证性能,字典需要对所使用的的哈希表(ht[0])进行
rehash操作:在不修改任何键值对的情况下,对哈希表进行扩容,尽量将比率维持在1:1左右。每次向字典添加新键值对都会进行检查,对于ht[0]的
size和used属性,ratio = used/size满足一下任何一个条件,激活rehash:- 自然
rehash:ratio >= 1, 且变量dict_can_resize为真- 在
BGSAVE、BGREWRITEAOF时,dict_can_resize会暂时设为假,为了最大化利用系统的copy on write机制,减少程序对内存的碰撞。
- 在
- 强制
rehash:ratio大于变量dict_force_resize_ratio(目前默认为5)。
- 自然
1.3.8 rehash执行过程
执行步骤:
- 创建一个比
ht[0]->table更大的ht[1]->table- 为
ht[1]->table分配空间至少是ht[0]->used的两倍
- 为
- 将
ht[0]->table中的键值对迁移到ht[1]->table - 将原有的
ht[0]的数据清空,并将ht[1]替换为新的ht[0]- 释放
ht[0]的空间 - 用
ht[1]来代替ht[0] - 创建新的哈希表,设置为
ht[1] - 将字典的
rehashidx属性设置为-1,标识rehash已停止
- 释放
1.3.9 渐进式rehash
rehash程序不是在激活只会就马上执行知道完成的,而是分多次、渐进式地完成- 添加键值对触发
rehash需要用户等很久不合理 - 服务器阻塞不可接受
- 添加键值对触发
渐进式
rehash由_dictRehashStep和dictRehashMilliseconds两个函数进行_dictRehashStep用于对数据库字典、以及哈希表的字典进行被动rehashdictRehashMilliseconds由Redis服务器常规任务程序(server cron jon)执行,用于数据库字典进行主动rehash
_dictRehashStep
- 每次执行
_dictRehashStep,ht[0]->table哈希表第一个不为空的索引上的所有节点就会全部迁移到ht[1]->table - 在
rehash开始之后,每次执行一次添加、查找、删除操作,_dictRehashStep都会执行一次
- 每次执行
dictRehashMilliseconds
dictRehashMilliseconds可以在指定的毫秒数内,对字典进行rehash
其他措施
rehash时,字典同时存在两个哈希表,所以查找、删除等操作除了在ht[0]上进行,还需要在ht[1]上进行。- 在执行添加操作时,新的节点直接添加到
ht[1]
1.3.10 字典的收缩
如果哈希表的可用节点比已用节点数大很多,也可以对哈希表进行
rehash来收缩字典收缩规则定义:
1 2 3 4 5 6 7 8 9// redis.c/htNeedResize int htNeedsResize(dict *dict) { long long size, used; size = dictSlots(dict); // 哈希表已用节点数量 used = dictSize(dict); // 哈希表大小 // 当哈希表的大小大于 DICT_HT_INITIAL_SIZE 并且字典的填充率低于 REDIS_HT_MINFILL 时 返回 1 return (size && used && size > DICT_HT_INITIAL_SIZE && (used*100/size < REDIS_HT_MINFILL)); }默认情况下,
DICT_HT_INITIAL_SIZE的值为10。也就是当字典填充率低于10%时,程序就可以对这个字典进行收缩操作的。
收缩和扩展的区别
- 扩展操作时自动触发的。而收缩操作时由程序手动执行
使用字典的程序可以决定何时对字典进行收缩
- 字典用于实现哈希键:每次从字典删除一个键值对,会立即执行
htNeedsResize函数,判断是否需要收缩 - 字典用于实现数据库键空间:由
redis.c/tryResizeHashTables函数决定
- 字典用于实现哈希键:每次从字典删除一个键值对,会立即执行
1.3.11 字典其他操作
1.3.12 字典的迭代
字典带有自己的迭代器实现(对字典迭代实际上是对字典所使用的的哈希表迭代)
- 迭代器首先迭代第一个哈希表,如果正在
rehash,就继续对第二个哈希表进行迭代 - 当迭代哈希表时,找到第一个不为空的索引,然后迭代这个索引上的所有节点
- 当这个索引迭代完了,继续查找下一个不为空的索引,如此循环,一直到整个哈希表都迭代完为止。
- 迭代器首先迭代第一个哈希表,如果正在
字典的迭代器有两种
- 安全迭代器:在迭代过程中,可以对字典进行修改
- 不安全迭代器:在迭代过程中,不对字典进行修改
迭代器的数据结构定义:
1 2 3 4 5 6 7 8 9typedef struct dictIterator { dict *d; //正在迭代的字典 int table, // 正在迭代的哈希表的号码(0或者1) index, // 正在迭代的哈希数组的索引 safe; // 是否安全? dictEntry *entry, // 当前哈希节点 *nextEntry; // 当前哈希节点的后继节点 } dictIterator;
迭代器API

1.3.13 小结
- 字典由键值对构成的抽象数据结构
- Redis中的数据库和哈希键都基于字典来实现
- Redis字典的底层实现为哈希表,每个字典使用两个哈希表。一般情况下只是用0号哈希表,只有
rehash时,才会同时使用0号和1号哈希表 - 哈希表使用
链地址法解决键冲突 Rehash可以用于扩展和收缩哈希表- 对哈希表的
rehash是分多次、渐进式地进行的
1.4 跳跃表
- 一种随机化的数据
- 以有序的方式在层次化的链表中保存元素
- 效率可以和平衡树媲美,查找、删除、添加都可以在对数期望时间下完成

- 表头(head):负责维护跳跃表的节点指针
- 跳跃表节点:保存元素值,以及多个层
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于底层的指针,为了提高查找效率,从高层开始访问,随着元素值范围缩小,慢慢降低层次
- 表尾:全部由NULL组成,表示跳跃表的末尾
1.4.1 跳跃表的实现
为了适应功能需要,redis做了修改:
- 允许重复的
score值:多个不同的member的score值可以相同 - 进行对比操作时,不仅要检查
score值,还要检查member - 每个节点都带有一个高度为1层的后退至真,用于从表尾方向向表头方向迭代
结构定义:
| |
跳跃表节点定义:
| |
操作这两个数据结构API:

1.4.2 跳跃表的应用
- 实现有序集数据类型
- 跳跃表将指向有序集的
score值和member域的指针作为元素,并以score值作为索引,对有序集元素进行排序。
- 跳跃表将指向有序集的
1.4.3 小结
- 跳跃表是一种随机化数据结构,查找、添加、删除都可以在对数期望时间下完成
- 跳跃表目前在Redis的唯一作用就是作为有序集类型的底层数据结构之一(另一个构成有序集的结构是字典)
- 为了适应功能,redis基于
William Pugh论文中描述的跳跃表进行修改:score值可重复- 对比元素同时检查
score和member - 每个节点带有高度为1的后退指针,用于从表尾向表头迭代
2、内存映射数据结构
- 虽然
内部数据结构非常强大,但是耗费内存。对于元素本身体积不大,代价昂贵。- Redis允许使用
内存映射数据结构来代替内部数据结构
- Redis允许使用
内存映射数据是一系列经过特殊编码的字节序列,节省大量内存- 因为
内存映射数据结构复杂得多,所以占用CPU时间要多
2.1 整数集合
- 整数集合(
ineset)用于有序、无重复地保存多个整数值。会根据元素的值,自动选择(调整)该用什么长度的整数类型保存数据。
2.1.1 整数集合的应用
Intset是集合键的底层实现之一,如果一个集合满足:
- 只保存整数数据
- 元素数量不多
2.2.2 数据结构和主要操作
- 定义
| |
encoding的值:
| |
content数组是实际保存数据的地方,特性:- 没有重复元素
- 元素在数组中从小到大排列
content数组的int8_t类型声明做为占位符使用。程序根据encoding的值,对content进行类型转换和指针运算。inset主要操作

2.1.3 intset 运行实例
- 创建新
insetintset *is = intsetNew();//intset.c/intsetNew
- 添加新元素到
intset。intset.c/intsetAdd- 处理情况
- 元素已存在,不做动作
- 元素不存在,并且添加新元素不需要升级
- 元素不存在,需要升级后,才能添加元素
intsetAdd需要维持intset->contents的以下性质- 没有重复元素
- 从小到大排序
- 处理情况
2.1.4 升级
intsetAdd发现新元素不能用现有编码方式保存,就会使用intsetUpgradeAndAdd函数升级intsetUpgradeAndAdd任务- 检测新元素需要编码类型
- 设置
encoding属性为新编码类型,根据新编码类型对整个contents数组进行内存重分配 - 调整
contents数组原有元素在内存中排列方式,从旧编码调整为新编码 - 将新元素添加到集合
2.1.5 关于升级
- 从较短整数到较长整数的转换,并不会更改元素里面的值
- 集合编码元素的方式,由元素中长度最大的那个值来决定
2.1.6 关于元素移动
- 元素移动不仅出现在升级(
intsetUpgradeAndAdd)操作中,还出现在对contents数组的增删(intsetAdd和intsetRemove)操作上。复杂度都不低于O(n)
2.1.7 其他操作
- 读取
_intsetGet:接受一个索引pos,根据intset->encoding的值进行指针运算,计算出给定索引的值。intsetSearch二分查找,判断元素的索引
- 写入
_intsetSet:接受一个索引pos以及一个new_value,将pos位置设置为new_value
- 删除
intsetRemove:删除单个元素。先intsetSearch获取需要删除元素索引,然后济宁内存移位操作,最后通过内存重新分配,调整数组长度
- 降级
Intset不支持降级操作
2.1.8 小结
Intset用于有序、无重复地保存多个整数值,它会根据元素的值,自动选择该用什么长度 的整数类型来保存元素。- 当一个位长度更长的整数值添加到
intset时,需要对intset进行升级,新intset中每个 元素的位长度都等于新添加值的位长度,但原有元素的值不变。 - 升级会引起整个
intset进行内存重分配,并移动集合中的所有元素,这个操作的复杂度 为 O(N) 。 Intset只支持升级,不支持降级。Intset是有序的,程序使用二分查找算法来实现查找操作,复杂度为 O(lg N) 。
2.2 压缩列表
Ziplist是由一系列特殊编码的内存块构成的列表- 一个
ziplist可以包含多个节点entry - 每个节点可以保存一个长度首先的字符数组或者整数
- 字符数组
- 长度小于等于 63 (2 6− 1)字节的字符数组
- 长度小于等于 16383 (2 14− 1)字节的字符数组
- 长度小于等于 4294967295 (2 32− 1)字节的字符数组
- 整数
- 4 位长,介于 0 至 12 之间的无符号整数
- 1 字节长,有符号整数
- 3 字节长,有符号整数
- int16_t 类型整数
- int32_t 类型整数
- int64_t 类型整数
- 字符数组
- 因为
ziplist节省内存。被哈希键、列表建、有序集合键作为初始化的底层实现来使用
2.2.1 ziplist的构成

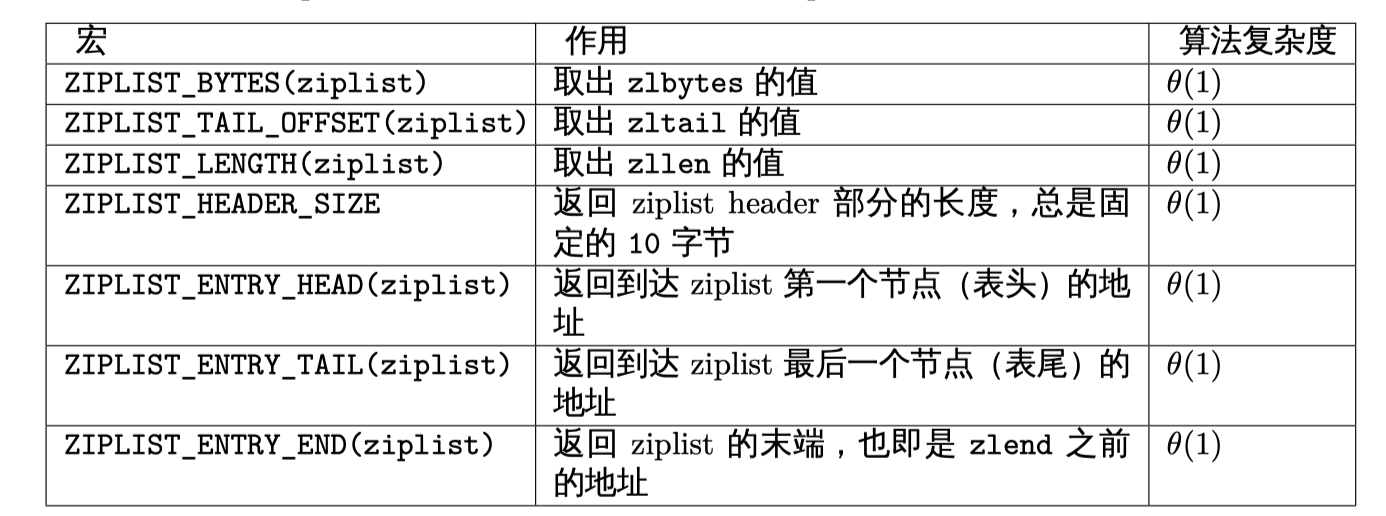
ziplist宏:
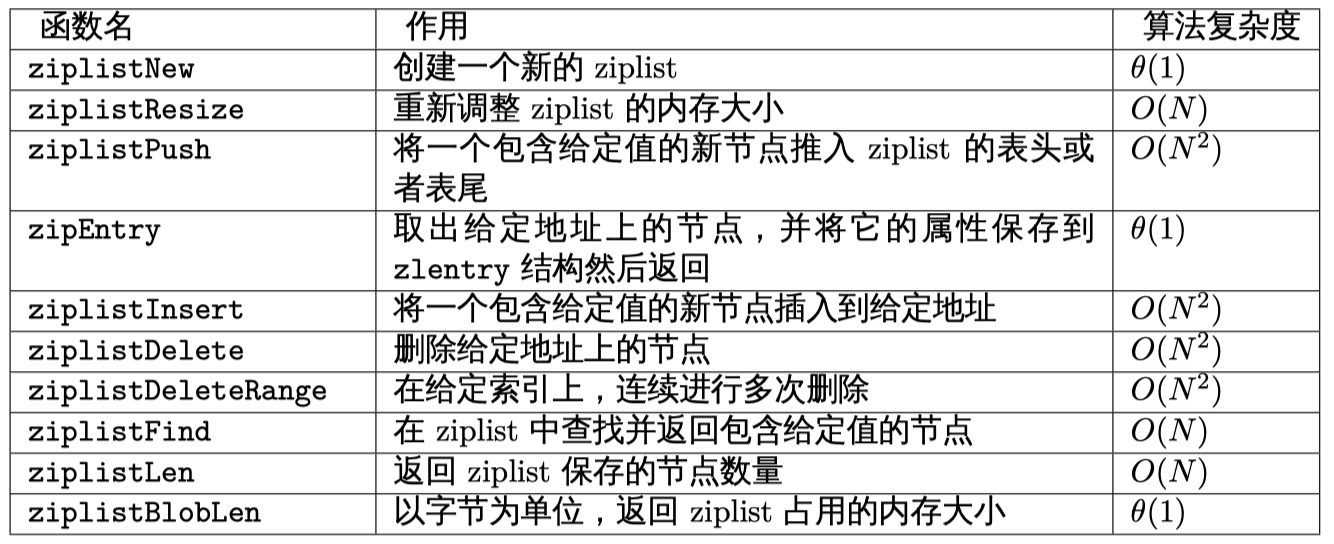
操作ziplist的函数
2.2.2 节点的构成

- pre_entry_length
- 记录了前一个节点的长度。通过这个值可以进行指针运算,从而跳转到上一个节点
- encoding
content部分数据类型
- length
content部分数据长度
- content
- 保存节点内容
2.2.3 创建新 ziplist
ziplistNew
2.2.4 将节点添加到末端
- 记录到达末端所需的偏移量
- 根据需要保存的值,计算所需的空间大小以及编码它前一个节点的长度所需的空间大小,然后进行内存重分配
- 设置新节点的各项属性
- 更新
ziplist的各项属性
2.2.5 将节点添加到某个/某些节点的前面
为新节点扩大
ziplist的空间设置新节点的各项属性
更新新节点到
ziplist。更新next节点的pre_entry_lengthpre_entry_length正好够新元素的长度pre_entry_length只有1字节长,新元素需要5字节pre_entry_length有5字节长,新元素需要1字节
1、3情况,直接更新
pre_entry_length。2情况需要对ziplist进行内存重分配,从next开始往后逐个判断是否扩展长度。所以复杂度为O(n^2)更新
ziplist各项属性
2.2.6 删除节点
- 定位目标节点,计算节点的空间长度
- 进行内存移位覆盖原本数据,然后内存重新分配,收缩多余空间
- 检查
next、next+1等后续节点是否满足新前驱节点的编码。类似添加操作,也会引起连锁更新。
2.2.7 遍历
- 可以对
ziplist进行从前向后的遍历,或者从后向前的遍历。
2.2.8 查找元素,根据值定位节点
- 类似遍历原理
2.2.9 小结
ziplist是由一系列特殊编码的内存块构成的列表,它可以保存字符数组或整数值,它还是 哈希键、列表键和有序集合键的底层实现之一。ziplist的结构ziplist的节点entry结构- 添加和删除
ziplist节点有可能会引起连锁更新,因此最坏复杂度O(n^2)。不过连锁更新概率不高,所以可以视为O(n)
3、Redis数据类型
3.1 对象处理机制
- 问题
- Redis必须让每个键都带有类型信息,使得程序可以检查键的类型,并为它选择合适的处理方式
- 需要根据数据类型的不同编码进行多态处理
- 为了解决上述问题,Redis构建了自己的类型系统,主要功能:
redisObject对象- 基于
redisObject对象的类型检查 - 基于
redisObject对象的显式多态函数 - 对
redisObject进行分配、共享和销毁的机制
3.1.1 redisObject数据结构,以及Redis的数据类型
- 定义
| |
type记录了对象所保存的值的类型
| |
encoding记录了对象所保存的值的编码
| |
- ptr是一个指针,指向实际保存值的数据结构,这个数据结构由
type属性和encoding属性决定
3.1.2 命令的类型检查和多态
- 当执行一个处理数据类型的命令时:
- 根据给定的
key,在数据字典查找redisObject,如果没找到返回NULL - 检查
redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误 - 根据
redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构 - 返回数据结构的操作结果作为命令的返回值
- 根据给定的
3.1.3 对象共享
- Flyweight 模式
- 通过预分配一个常见的值对象,并在多个数据结构之间共存这些对象,避免重复分配,也节约CPU时间
- Redis预分配的值对象
- 各种命令的返回值。
OK、ERROR等 - 包括0在不,小于
redis.h/REDIS_SHARED_INTEGERS的所有整数。(默认10000)
- 各种命令的返回值。
- 共享对象只能被带指针的数据结构使用。
3.1.4 引用计数以及对象的销毁
- 问题
redisObject用作数据库的键或者值,生命周期非常长,C语言本身没有自动释放内存的相关机制- 对象的引用次数问题
- 解决方案。使用引用计数技术负责维持和销毁对象
- 每个
redisObject都有一个refcount属性,记录被引用次数 - 新建对象,
refcount值为1 - 对一个对象进行共享时,
refcount加一 - 当用完一个对象之后,或者取消引用之后,程序对对象的
refcount减一 - 当对象的
refcount降至0时,这个redisObject以及它所引用的数据结构的内存,就会被释放
- 每个
3.1.5 小结
- Redis使用自己实现的对象机制来实现类型判断、命令多态和基于引用计数的垃圾回收。
- 一种 Redis 类型的键可以有多种底层实现
- Redis 会预分配一些常用的数据对象,并通过共享这些对象来减少内存占用,和避免频繁 地为小对象分配内存。
3.2 字符串
REDIS_STRING是Redis使用最广泛的数据类型
3.2.1 字符串编码
- 字符串类型分别使用
REDIS_ENCODING_INT和REDIS_ENCODING_RAW两种编码REDIS_ENCODING_INT使用long类型来保存long类型值REDIS_ENCODING_RAW使用sdshdr结构来保存sds(char *)、long long、double、long double类型
3.2.2 编码的选择
- 新创建的字符串默认使用
REDIS_ENCODING_RAW编码 - 在字符串作为键或者值保存进数据库时,会尝试转为
REDIS_ENCODING_INT
3.2.3 字符串命令的实现
- 通过包装
sds数据结构的操作函数来实现
3.3 哈希表
REDIS_HASH是HSET、HLEN等命令的操作对象,它使用REDIS_ENCODING_ZIPLIST(压缩列表)和REDIS_ENCODING_HT(字典)两种编码方式
3.3.1 字典编码的哈希表
- 当使用字典编码时,程序将哈希表的键保存为字典的键,哈希表的值保存为字典的值
3.3.2 压缩列表编码的哈希表
- 程序将键和值一同推入压缩列表,从而形成保存哈希表所需的键值对结构
- 新添加的键值对会被添加到压缩列表的表尾
- 当进行查找/删除或者更新操作时,程序先定位到键的位置,然后在通过对键的位置来定位值的位置

3.3.3 编码的选择
- 创建空白哈希表,默认使用
REDIS_ENCODING_ZIPLIST。 - 满足以下任何一个条件,编码会切换为
REDIS_ENCODING_HT:- 哈希表中的某个键或者某个值的长度大于
server.hash_max_ziplist_value(默认64) - 压缩列表中的节点数量大于
server.hash_max_ziplist_entries(默认512)
- 哈希表中的某个键或者某个值的长度大于
3.3.4 哈希命令的实现
- 对字典和压缩列表操作函数的封装,以及在两种编码之间进行转换的函数
3.4 列表
REDIS_LIST是LPUSH、LRANGE等命令的操作对象,它使用REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST这两种方式编码
3.4.1 编码的选择
- 默认使用
REDIS_ENCODING_ZIPLIST - 满足以下任一条件,会转换为
REDIS_ENCODING_LINKEDLIST- 新增字符串长度超过
server.list_max_ziplist_value(默认64) ziplist包含的节点超过server.list_max_ziplist_entries(默认值512)
- 新增字符串长度超过
3.4.2 列表命令的实现
- 两种底层实现的抽象方式和列表的抽象方式非常接近,所以列表命令几乎就是通过一对一 地映射到底层数据结构的操作来实现的
3.4.3 阻塞的条件
BLPOP、BRPOP和BRPOPLPUSH三个命令都可能造成客户端被阻塞,以下将这些命令统 称为列表的阻塞原语。- 阻塞原语并不是一定会造成客户端阻塞:
- 只有当这些命令并用于空列表时,才会阻塞客户端
- 如果被处理的列表不为空,就执行物阻塞版本的
LPOP、RPOP或RPOPLPUSH命令
3.4.4 阻塞
- 当一个阻塞原语的处理目标为空键时,执行该阻塞原语的客户端就会被阻塞
- 阻塞一个客户端需要执行的步骤
- 将客户端设置为“正在阻塞”,并记录阻塞客户端的各个键以及阻塞的最长时限
- 将客户端的信息记录到
server.db[1]->blocking_keys中(其中i为客户端所使用的的数据库号码) - 继续维持客户端和服务端之间的网络连接,但不在向客户端传送任何信息,造成客户端阻塞
- 客户端脱离阻塞状态的方法:
- 被动脱离:其他客户端为造成阻塞的键推入了新元素
- 主动脱离:超过最大阻塞时间
- 强制脱离:客户端强制终止和服务器的链接,或者服务器停机
3.4.5 阻塞因LPUSH、RPUSH、LINSERT等添加命令而被取消
- 这三个添加新元素到列表命令底层都是由
pushGenericCommand函数实现 - 当向一个空键推入新元素时,该函数执行两件事:
- 检查键是存在于
server.db[i]->blocking_keys字典里,如果有,为这个键创建一个redis.h/readyList结构,并将它添加到server.ready_keys链表中。 - 将给定的值添加到列表键中
- 检查键是存在于
readyList结构定义:
| |
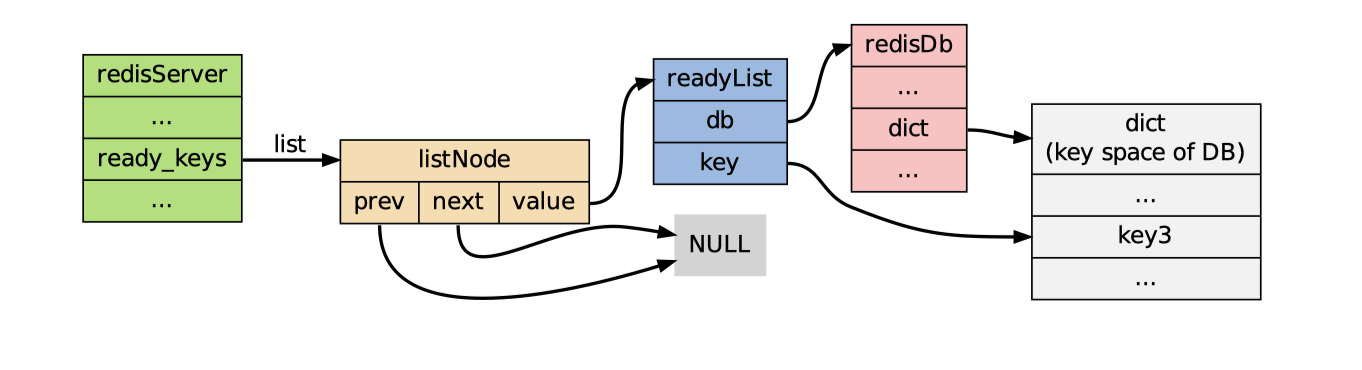
- Redis主进程执行完
pushGenericCommand函数后,继续调用handleClientsBlockedOnLists:- 如果
server.ready_keys不为空,弹出表头元素,并取出元素中的readyList值 - 根据
readyList在server.blocking_keys中查找因为key被阻塞的客户端(以链表形式保存) - 如果
key不为空,弹出一个元素,并弹出客户端链表的第一个客户端,然后将被弹出的元素返回给被弹出客户端作为阻塞原语的返回值 - 根据
readyList结构的属性,删除server.blocking_keys中响应的客户端数据,取消客户端的阻塞状态 - 继续执行步骤3和4直到
key没有元素可弹出,或者没有阻塞的客户端 - 继续执行步骤1,直到
server.ready_keys链表所有的readyList都被处理完
- 如果
3.4.6 先阻塞先服务(FBFS)策略
3.4.7 阻塞因超过最大等待时间而被取消
- 每次Redis常规操作函数(server cron job)执行时,程序都会检查所有连接到服务器的客户端,查看哪些处于“正在阻塞”状态的客户端的最大阻塞时限是否已经过期
- 如果已经过期,给客户端返回空白回复,然后撤销对客户端阻塞
3.5 集合
REDIS_SET是SADD、SRANDMEMBER等命令的操作对象,它使用REDIS_ENCODING_INTSET和REDIS_ENCODING_HT两种方式编码
3.5.1 编码的选择
- 第一个添加到集合的元素,决定了创建集合所使用的编码
- 第一个元素可以表示成
long long类型,集合初始编码为REDIS_ENCODING_INTSET - 否则,初始编码为
REDIS_ENCODING_HT
- 第一个元素可以表示成
3.5.2 编码的切换
REDIS_ENCODING_INTSET切换到REDIS_ENCODING_HT。以下任一条件:intset保存的整数值个数超过server.set_max_intset_entries(默认512)- 试图往集合添加一个新元素,并且这个元素不能被表示为
long long类型
3.5.3 字典编码的集合
- 当使用
REDIS_ENCODING_HT编码时,集合将元素保存在字典的键里面,值统一为NULL
3.5.4 集合命令的实现
- 主要对
intset和dict两个数据结构的操作函数的包装,以及一些两种编码之间进行转换的函数
3.5.5 求交集算法
SINTERSINTERSTORE- O(n^2)
3.5.6 求并集算法
SUNIONSUNIONSTORE- O(n)
3.5.7 求差集算法
SDIFFSDIFFSTORE- O(n^2)
3.6 有序集
REDIS_SET是ZADD、ZCOUNT等命令的操作对象,它使用REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST两种方式编码:
3.6.1 编码的选择
- 通过
ZADD添加第一个元素到空key时,决定- 满足以下条件,使用
REDIS_ENCODING_ZIPLIST- 服务器属性
server.zset_max_ziplist_entries的值大于0 (默认128) - 元素的
member长度小于服务器属性server.zset_max_ziplist_value的值(默认64)
- 服务器属性
- 否则,创建
REDIS_ENCODING_SKIPLIST编码的有序集
- 满足以下条件,使用
3.6.2 编码的转换
REDIS_ENCODING_ZIPLIST转换为REDIS_ENCODING_SKIPLIST,满足以下任一条件:ziplist所保存的元素超过server.zset_max_ziplist_entries(默认128)- 新添加元素
member的长度大于server.zset_max_ziplist_value(默认64)
3.6.3 ZIPLIST编码的有序集
- 每个有序集元素以两个相邻的
ziplist节点表示,第一个节点保存元素的member域,第二个元素保存元素的score域 - 多个元素之间按
score值从小到大排序,如果两个元素的score相同,那么按字典序对member进行对比,决定元素顺序
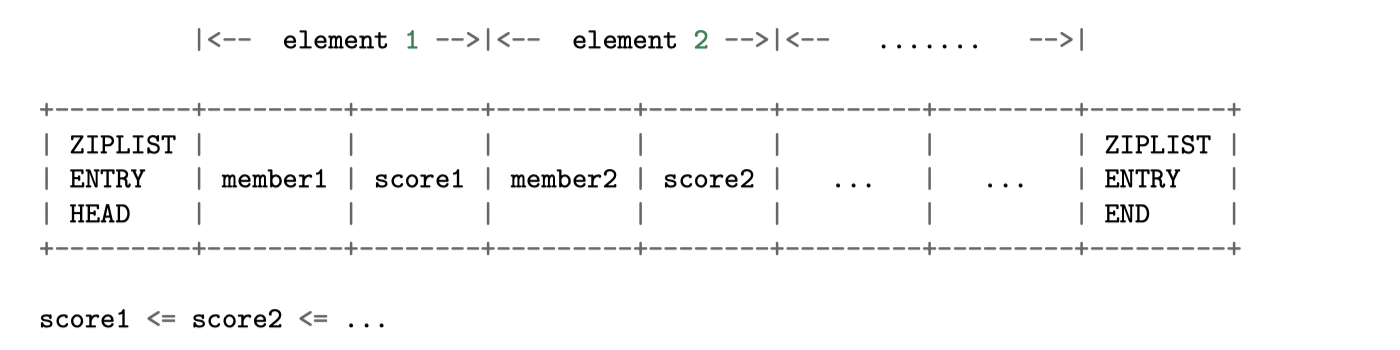
- 查找复杂度O(n)
- 添加/删除/更新复杂度都不低于O(n)
3.6.4 SKIPLIST编码的有序集
当使用
REDIS_ENCODING_SKIPLIST编码时,有序集元素由redis.h/zset结构来保存:1 2 3 4typedef struct zset { dict *dict; // 字典 zskiplist *zsl; // 跳跃表 } zset;
zset同时使用字典和跳跃表两个数据结构来保存有序集元素元素的成员由一个
redisObject结构表示,元素的score则是一个double类型的浮点数,字典和跳跃表两个结构通过将指针共同指向这两个值来节约空间字典结构:
member作为键,score作为值,有序集可以在O(1)负责度内:- 检查
member是否存在 - 取出
member对应的score值 (ZSCORE)
- 检查
跳跃表:可以让有序集支持一下操作:
- O(logN)期望时间、O(n)最坏时间内根据
score对member进行定位 - 范围行查找和处理操作
ZRANGEZRANKZINTERSTORE等
- O(logN)期望时间、O(n)最坏时间内根据
4、功能的实现
4.1 事务
- Redis通过
MULTI、DISCARD、EXEC、WATCH四个命令来实现事务功能
4.1.1 事务
事务提供一种“将多个命令打包,然后一次性、按顺序地执行”的机制,并且事务在执行期间不会主动终端—服务器在执行完事务中所有的命令后,才会继续处理其他客户端的其他命令
事务执行阶段
- 开始事务
- 命令入队
- 执行事务
4.1.2 开始事务
WATCH命令的执行标记着事务的开始- 这个命令唯一做的,将客户端
REDIS_MULTI选项打开,让客户端从非事务状态切换到事务状态
4.1.3 命令入队
- 当客户端处于
非事务状态时,所有发送给服务端的命令都会立即被执行 - 当客户端处于
事务状态时,服务器在收到客户端命令时,不会立即执行,而是将这些命令全部让如一个事务队列,然后返回QUEUED,表示命令已入队 - 事务队列是一个数组,每个元素包含三个属性
- 要执行的命令(cmd)
- 命令的参数(argv)
- 参数的个数(argc)
4.1.4 执行事务
- 不是所有命令都会被放入事务队列:
EXEC、DISCARD、MULTI、WATCH这四个命令会被立即执行 - 当
EXEC命令执行时- 服务器根据客户端所保存的事务队列,以先进先出(FIFO)方式执行
4.1.5 在事务和非事务状态下执行命令
- 无论事务状态还是非事务状态,Redis命令都是由同一个函数执行,所以他们共享服务器一般配置,比如
AOF配置、RDB配置以及内存限制等 - 事务中的命令和普通命令区别:
- 非事务状态下的命令以单个命令为单位执行,前一个命令和后一个的客户端不一定是同一个;事务状态则是以事务为单位:除非当前事务执行完毕,否则服务器不会中断事务,也不会执行其他客户端的其他命令。
- 非事务状态下,执行命令结果立即返回给客户端;事务状态下所有命令的结果集合到回复队列,在做
EXEC命令的结果返回客户端。
4.1.6 事务状态下的DISCARD、MULTI、WATCH
DISCARD用于取消一个事务,清空客户端的整个事务队列,然后将客户端从事务状态调整回非事务状态,最后返回OK- Redis的事务不可嵌套。事务状态下发送
MULTI,服务器只是简繁返回错误,然后继续等待其他命令入队。不会造成事务失败或修改 WATCH只能在客户端进入事务之前执行,否则会引发错误。但它不会造成事务失败,也不会修改事务队列已有数据。
4.1.7 带WATCH的事务
WATCH命令用于在事务开始之前监视任意数量的键:当调用EXEC命令执行事务时,如果任意一个被监视的键已经被其他客户端修改了,那么整个事务不在执行,直接返回失败。
4.1.8 WATCH命令的实现
- 在每个数据库
redis.h/redisDb的数据类型中,保存了一个watched_keys字典,字典的键时整个数据库被监视的键,字典的值则是一个链表,链表中保存了所有监视这个键的客户端。 WATCH命令的作用就是:将当前客户端和要监视的键在watched_keys中进行关联
4.1.9 WATCH的触发
- 在任何对数据库键空间进行修改的命令成功执行之后,
multi.c/touchWatchKey函数都会被调用,它检查数据库的watched_keys字典,看是否有客户端在监视已经被命令修改的键,如果有,程序将所有监视这个键的客户端的REDIS_DIRTY_CAS选项打开 - 当客户端发送
EXEC命令、出发事务执行时,会对客户端状态进行检查- 如果
REDIS_DIRTY_CAS被打开,直接返回空回复,表示事物执行失败 - 如果
REDIS_DIRTY_CAS没有打开,说明安全,正式执行事务
- 如果
- 最后,当一个客户端结束他的事务时,无论事务成功失败,
watched_keys字典中和这个客户端有关的资料都会别清除
4.1.10 事务的ACID性质
- 原子性(Atomicity)
- 单个Redis命令的执行事原子性的,但Redis没有在事务上增加任何维持原子性的机制,所以Redis事务不是原子性的
- 如果一个事务队列所有命令都被成功执行,那么称这个事务执行成功
- 如果Redis服务器进程在执行事务过程中被停止,那么事务执行失败
- 事务失败时,Redis也不会进行任何的重试或者回滚操作
- 一致性(Consistency)
- Redis的一致性:入队错误、执行错误、Redis进程被终结
- 入队错误
- 在命令入队时,如果客户端发送错误的命令,服务端会向客户端返回一个出错信息,并且将客户端的事务状态设置为
REDIS_DIRTY_EXEC - 当客户端执行
EXEC时,Redis拒绝执行状态为REDIS_DIRTY_EXEC的事务,并返回失败信息 - 因此,带有不正确入队命令的事务不会被执行,也不会影响数据库的一致性
- 在命令入队时,如果客户端发送错误的命令,服务端会向客户端返回一个出错信息,并且将客户端的事务状态设置为
- 执行错误
- 如果命令在事务执行过程中发生错误,Redis只会将错误包含在事务的结果中,不会引起事务的中断或整个失败
- 不会影响已执行事务命令的结果,也不会影响后面要执行的事务命令
- 所以它对事务的一致性没有影响
- Redis进程被终结
- 根据Redis持久化模式:
- 内存模式:没有任何持久化机制,重启后数据库总是空白,所以数据总是一致
- RDB模式:事务进行中,不会中断Redis执行保存RDB保存工作,所以数据库是一致的
- AOF模式:因为AOF后台进行:
- 事务语句未被写入AOF文件,还原后是一致的
- 事务语句被写入AOF文件。重启Redis,程序会检测AOF文件并不完整,Redis会退出,并报告错误。需要使用
redis-check-aof工具将部分成功事务命令移除之后,才能再次启动服务器。还原后是一致的
- 根据Redis持久化模式:
- 隔离性(Isolation)
- Redis是单进程程序,并且保证执行事务时不会对事务进行中断,所以具有隔离性
- 持久性(Durability)
- 因为事务只是用队列包裹了一组Redis命令,没有提供任何额外的持久性功能,所以事务的持久性由Redis所使用的的持久化模式决定
- 内存模式:不持久
- RDB模式:不持久
- AOF模式:异步保存有时间间隔,也不持久
- 因为事务只是用队列包裹了一组Redis命令,没有提供任何额外的持久性功能,所以事务的持久性由Redis所使用的的持久化模式决定
4.1.11 小结
- 事务提供一种将多个命令打包,然后一次性、有序地执行的机制
- 事务执行过程中不会被中断,所有事务命令执行完之后,事务才能结束
- 多个命令会被入队到事务队列中,然后按先进先出(
FIFO)的顺序执行。 - 带
WATCH命令的事务会将客户端和被监视的键在数据库的watched_keys字典中进行关 联,当键被修改时,程序会将所有监视被修改键的客户端的REDIS_DIRTY_CAS选项打开。 - 只有在客户端的
REDIS_DIRTY_CAS选项未被打开时,才能执行事务,否则事务直接返回 失败。 - Redis 的事务保证了 ACID 中的一致性(C)和隔离性(I),但并不保证原子性(A)和 持久性(D)。
4.2 订阅与发布
- Redis通过
PUBLISH、SUBSCRIBE等命令实现了订阅与发布模式
4.2.1 频道的订阅与信息发送
SUBSCRIBE命令可以让客户端订阅任意数量的频道- 当有消息通过
PUBLISH命令发送给频道时,这个消息就会被发送给订阅他的所有客户端
4.2.2 订阅频道
每个Redis服务器进程都维持这个一个表示服务器状态的
redis.h/redisServer结构,结构的pubsub_channels属性是一个字典,用于保存订阅频道的信息1 2 3struct redisSercer { dict *pubsub_channels; }字典的键为正在被订阅的频道,值为一个链表,保存了所有订阅这个频道的客户端
当客户端调用
SUBSCRIBE时,程序就将客户端和要订阅的频道在pubsub_channels字典中关联起来
4.2.3 发送信息到频道
- 首先根据
channel定位到字典的键 - 将信息发送给字典链表中的所有客户端
4.2.4 退订频道
UNSUBSCRIBE,从pubsub_channels字典的给定频道(键)中,删除关于当前客户端的信息
4.2.5 模式的订阅与信息发送
4.2.6 订阅模式
redisServer.pubsub_patterns属性是一个链表,保存着所有和模式先关的信息1 2 3struct redisServer { list *pubsub_patterns; }
链表的每个节点都包含一个
redis.h/pubsubPattern结构1 2 3 4typedef struct pubsubPattern { redisClient *client; // 订阅模式的客户端 robj *pattern; // 被订阅的模式 } pubsubPattern;
调用
PSUBSCRIBE时,程序就创建一个包含客户端和被订阅模式的pubsubPattern结构,并将该结构添加到redisServer.pubsub_patterns链表中
4.2.7 发送信息到模式
PUBLISH
4.2.8 退订模式
PUNSUBSCRIBE
4.2.9 小结
- 订阅信息由服务器进程维持的
redisServer.pubsub_channels字典保存,字典的键为被订阅的频道,字典的值为订阅频道的所有客户端 - 当有新消息发送到频道时,程序遍历频道所对应的所有客户端,然后将消息发送到订阅频道的客户端上
- 订阅模式的信息由服务器进程维持的
redisServer.pubsub_patterns链表来保存,链表的每个节点都保存一个pubsubPattern结构。 - 当有新消息发送到频道时,除了订阅频道的客户端回收到消息之外,所有订阅了匹配频道的模式的客户端,也同样会收到消息
- 退订频道和退订模式分别的订阅频道和订阅模式的反操作
4.3 Lua脚本
4.3.1 初始化Lua环境
- 在初始化Redis服务器时
- Redis对Lua环境进行了一系列修改,包括添加数据库、更换随机函数、保护全局变量等
- 初始化步骤
- 调用
lua_open函数,创建一个新的Lua环境 - 载入指定的Lua函数库,包括:
- 基础库(
base lib) - 表格库(
table lib) - 字符串库(
string lib) - 数学库(
math lib) - 调试库(
debug lib) - 用于处理JSON的
cjson库 - 在Lua值和C结构(
struct)之间进行转换的struct库 - 处理
MessagePack数据的cmsgpack库
- 基础库(
- 屏蔽一些可能对Lua环境产生安全问题的函数,比如
loadfile - 创建一个Redis字典,保存Lua脚本,并在复制(
replication)脚本时使用。字典的键为SHA1校验和,字典的值为Lua脚本 - 创建一个redis全局表格到Lua环境,表格中包含了各种对Redis进行操作的函数
- 用Redis自己定义的随机生成函数,替换
math表原有的math.random函数和math.randommseed函数 - 创建一个对Redis多批量回复(
multi bulk reply)进行排序的辅助函数 - 对Lua环境中的全局变量进行保护,以免被传入的脚本修改
- 因为Redis命令必须客户端执行,所以需要在服务器状态中创建一个无网络链接的伪客户端(
fake client),专门用于执行Lua脚本中包含的Redis命令。 - 将Lua环境的指针记录到Redis服务器的全局状态中,等候Redis的调用。
- 调用
4.3.2 脚本的安全性
- 问题
- 如果一段Lua脚本带有随机性质或作用,那么当这段脚本在附属节点运行时,或者从AOF文件载入重新运行时,带到的结果可能和之前运行的结果完全不同
- 解决
- Redis对Lua环境所能执行的脚本做了一个严格的限制:所有的脚本都必须是无副作用的纯函数(
pure function)
- Redis对Lua环境所能执行的脚本做了一个严格的限制:所有的脚本都必须是无副作用的纯函数(
- 策略
- 不提供访问系统状态的库(比如系统时间库)
- 进制使用
loadfile函数 - 阻止带有随机性质命令的脚本执行
- 如果脚本执行带有随机命令的读,会先被执行一个自动的字典序排序,保证输出结果有序
- 用Redis自己定义的随机生成函数,替换Lua环境中
math表原有的随机函数。新函数性质:每次执行Lua脚本,除非显式地调用math.randomseed,否则math.random生成的伪随机数序列总是相同的。
- 保证:
- 无副作用
- 没有有害的随机性
- 对于同样的输入参数和数据集,总是产生相同的写入命令
4.3.3 脚本的执行
EVAL、EVALSHA执行Lua脚本EVALSHA基于EVAL
4.3.4 EVAL命令的实现
EVAL的执行分为以下步骤:- 为输入脚本定义一个Lua函数
- 执行这个Lua函数
定义Lua函数
函数名以
f_为前缀,后跟脚本的SHA1校验和1 2 3 4// EVAL "return 'hello world'" 0 function f_5332031c6b470dc5a0dd9b4bf2030dea6d65de91() return 'hello world' end
好处:
- 执行步骤简单,只要调用和脚本相对应的函数
- Lua环境保持清洁,已有的脚本和新加入的脚本不会互相干扰,可以将重置Lua环境和调用Lua GC的次数降到最低
- 如果某个脚本对应的函数的Lua被定义过,只需要记得这个脚本的
SHA1校验和
执行Lua函数
- 将
EVAL命令输入的KEYS参数和ARGV参数以全局数组的方式传入到Lua环境中 - 设置伪客户端的目标数据为调用者客户端的目标数据库
- 为Lua环境装载超时钩子,保证脚本执行超时可以杀死脚本,或者停止Redis服务器
- 执行脚本对应的Lua函数
- 如果脚本有
SELECT命令,那么需要对调用者客户端的目标数据库进行更新 - 执行清理操作:清除钩子;清除指向调用者客户端的指针等
- 将Lua函数指定所得结果转换成Redis回复,传给客户端
- 对Lua环境进行一次单步的渐进式GC
- 将
4.3.5 EVALSHA命令的实现
- 只要脚本对应的函数在Lua里定义过,即使用户不知道脚本的内容本身,也可以直接通过脚本的
SHA1校验和来掉调用
4.3.6 小结
- 初始化Lua脚本环境需要一系列步骤
- Redis通过一系列措施保证Lua脚本无副作用,也没有有害的写随机性
EVAL命令为输入脚本定义一个Lua函数,然后通过函数执行脚本EVALSHA通过构建函数名,直接调用Lua中定义的函数,从而执行脚本
4.4 慢查询日志
- 慢查询日志是Redis提供的一个用于观察系统性能的功能
4.4.1 相关数据结构
- 慢日志结构定义:
| |
记录服务器状态的
redis.h/redisServer结构1 2 3 4 5 6struct redisServer { list *slowlog; // 保存慢查询日志的链表 long long slowlog_entry_id; // 慢查询日志当前id值 long long slowlog_log_slower_than; // 慢查询时间限制 unsigned long slowlog_max_len; // 慢查询日志最大条目数量 }slowlog从新到旧排序链表slowlog_entry_id在创建慢日志后加一,用于产生慢查询日志ID(SLOW LOG之后被重置)slowlog_log_slower_than:命令执行时间上限slowlog_max_len:日志数量等于这个值,添加新日志,最旧的日志会被删除
4.4.2 慢查询日志的记录
- Redis记录命令执行前的时间,执行完成后计算耗费时间
duration,并传给slowlogPushEntryIfNeed函数 - 如果
duration超过server.slowlog_log_slower_than,slowlogPushEntryIfNeed就会创建一条心的慢查询日志,加入慢查询日志链表
4.4.3 慢查询日志的操作
- 查看日志 O(n)
- 清空日志 O(n)
- 获取日志数量 O(1)
4.4.4 小结
- Redis用一个链表以
FIFO的顺序保存所有的慢查询日志 - 每条慢查询日志记录执行超时的命令、命令的参数、命令执行时间、命令所消耗的时间等信息
5、内部运作机制
5.1 数据库
5.1.1 数据库的结构
Redis中的每个数据库,都是由一个
redis.h/redisDb结构表示:1 2 3 4 5 6 7 8 9typedef struct redisDb { int id; // 保存着数据库以整数表示的号码 dict *dict; // 保存着数据库中的所有键值对数据。也被称为键空间 dict *expires; // 保存着键的过期信息 dict *blocking_keys; // 实现列表阻塞原语 dict *ready_keys; dict *watched_keys; // 用于MATCH命令。事务 } redisDb;
5.1.2 数据库的切换
redisDb结构的id保存着数据库的号码- Redis初始化时,会创建
redis.h/REDIS_DEFAULT_DBNUM个数据库,并将所有数据库保存到redis.h/redisServer.db数组中,每个数据库id从0到REDIS_DEFAULT_DBNUM - 1 - 当执行
SELECT number时,程序使用redisServer.db[number]来切换数据库
5.1.3 数据库键空间
- Redis是键值对数据库,所以它的数据库本身也是一个字典(
key space)- 字典的键是一个字符串对象
- 字典的值则可以使包括字符串、列表、哈希表、集合、有序集在内的任意一种Redsi类型对象
redisDb结构的dict属性,保存着数据库所有的键值对数据
5.1.4 键空间的操作
因为数据库本身是一个字典,所以对数据库的操作基本上都是对字典的操作,加上一些维护操作
添加新键
删除键
更新键
取值
其他操作
FLUSHDBRANDOMKEYDBSIZEEXISTSRENAME
5.1.5 键的过期时间
EXPIRE、PEXPIRE、EXPIREAT、PEXPIREAT
5.1.6 过期时间的保存
redisDb结构的expires字典里expires字典的键是一个执行dict字典里某个键的指针,字典的值是过期时间long long类型
5.1.7 设置生存时间
- Redis有四个命令设置键的生存时间和过期时间
- 但是,
expires字典的值只保存“以毫秒为单位的过期UNIX时间戳”
5.1.8 过期键的判定
- 通过
expires字典,通过以下步骤检查- 检查键是否在
expires字典;如果存在,那么取出键的过期时间 - 通过与当前UNIX时间戳对比没判断是否过期
- 检查键是否在
5.1.9 过期键的清除
- 三种删除方式
- 定时删除:在设置键的过期时间时,创建一个定时事件,当过期时间到达时,由事件处理器自动执行键的删除操作
- 惰性删除:放任键过期不管,但是在每次从
dict字典取出键时,检查是否过期,过期则删除并返回空 - 定期删除:每隔一段时间,对
expires字典进行检查,删除过期键
- 定时删除
- 对内存最友好:因为能保证过期键第一时间被删除
- 缺点:
- 对CPU时间最不友好:因为删除操作可能会占用大量的CPU时间
- 目前Redis事件处理器对时间事件的实现方式–无序链表,查找复杂度O(n),不适合用来处理大量时间事件
- 惰性删除
- 对CPU最友好:只会在取出键时进行检查
- 缺点
- 对内存最不友好:内存已知占用不被释放
- 定期删除
- 上述两种的折中策略
- 每隔一段时间执行一次删除操作,并通过限制删除操作执行的时长和频率,来减少删除操作对CPU时间的影响
- 通过定期删除过期键,有效的减少内存浪费
- Redis使用的策略
- 惰性删除 + 定期删除
5.1.10 过期键的惰性删除策略
db.c/expireIfNeeded函数。- 所有命令在读取或写入数据库之前都会调用
expireIfNeeded函数对键进行检查 expireIfNeeded的作用是,如果输入键过期的话,将键、值、键保存在expires字典中的过期时间都删除掉
5.1.11 过期键的定期删除策略
redis.c/activeExpireCycle函数。- 每当Redis的例行处理程序
serverCron执行时,activeExpireCycle都会被调用 - 这个函数在规定时间限制内,尽可能地遍历各个数据库的
expires字典,随机的检查一部分键的过期时间,并删除其中的过期键
5.1.12 过期键对AOF、RDB和复制的影响
- 更新后的RDB文件
- 在创建RDB文件时,程序会对键进行检查,过期的键不会被写入到更新后的RDB文件中
- AOF文件
- 过期键在被惰性删除或定期删除之前,不会有任何影响,AOF不会被修改
- 过期键被删除后,程序会向AOF文件追加一条DEL命令
- AOF重写
- 重写时,程序会检查键,过期的键不会被保存到重写后的AOF文件
- 复制
- 过期键的删除由主节点统一控制
- 如果是主节点,它删除一个过期键后,会显式地向所有附属节点发送一个
DEL命令 - 如果是附属节点,碰到过期键,会返回已过期的回复,但是不会删除。
- 如果是主节点,它删除一个过期键后,会显式地向所有附属节点发送一个
- 过期键的删除由主节点统一控制
5.1.13 数据库空间的收缩和扩展
- 字典的 扩展/收缩规则
redis.c/tryResizeHashTables函数检查数据库是否需要收缩- 每次
redis.c/serverCron函数运行时,被调用
5.1.14 小结
- 数据库主要由
dict和expires两个字典构成,dict保存键值对,expires保存键的过期时间 - 数据库的键总是一个字符串对象,值可以使任意一种Redis数据类型,包括字符串、哈希表、集合、列表、有序集
expires的某个键和dict的某个键共同指向同一个字符串对象,而expires键的值则是该键以毫秒计算的UNIX过期时间戳- Redis使用惰性删除和定期删除两种策略来删除过期的键
- 更新后的RDB文件和重写后的AOF文件不会保留过期的键
- 当一个过期的键被删除之后,程序会追加一条新的
DEL命令到AOF文件 - 当主节点删除一个过期键后,会显式的发送一条
DEL命令到所有附属节点 - 附属节点发现过期键后,不会删除,而是等待主节点发来
DEL命令,保证数据一致 - 数据库的
dict和expires字典的扩展策略和普通字典一样。当填充百分比不足10%时,将可用节点数量减少至大于等于当前已用节点数量。
5.2 RDB
- RDB核心是
rdbSave和rdbLoad函数,前者用于生成RDB文件到磁盘,后者用于将RDB文件中的数据重新载入到内存
5.2.1 保存
- 如果RDB文件已存在,新的RDB文件会替换已有的
- RDB保存文件期间,主进程会被阻塞,知道保存完成为止
SAVE直接调用rdbSave,阻塞Redis主进程,知道保存完成为止BGSAVE则fork出一个子进程,子进程负责调用rdbSave,并在保存完成后向主进程发送信号,通知保存已完成。
5.2.2 SAVE、BGSAVE、AOF写入、BGREWRITEFOF
SAVE
SAVE执行时,新的SAVE、BGSAVE、BGREWRITEAOF调用不会产生任何多用- AOF写入是后台线程完成,
BGREWRITEAOF由子进程完成,所以SAVE执行过程中,AOF写入、BGREWRITEAOF可以同时进行
BGSAVE
- 在指向
SAVE之前,服务器会检查BGSAVE是否正在执行,如果是,不调用rdbSave,向客户端返回出错信息 - 当
BGSAVE执行时,调用新的BGSAVE的客户端也会收到出错信息 BGSAVE执行时,BGREWRITEAOF的重写请求会被延迟到BGSAVE执行完毕BGREWRITEAOF执行时,调用BGSAVE的客户端将收到出错信息BGREWRITEAOF和BGSAVE不同时执行时处于性能考虑- 并发两个子进程,并且两个子进程都同时进行大量的磁盘写入,性能问题
- 在指向
5.2.3 载入
- Redis服务器启动时,
rdbLoad函数就会被执行,它读取RDB文件,将文件中的数据库数据载入到内存中 - 在载入期间, 服务器每载入 1000 个键就处理一次所有已到达的请求, 不过只有
PUBLISH、SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE、PUNSUBSCRIBE五个命令的请求会被正确地处理, 其他命令一律返回错误。等到载入完成之后,服务器才会开始正常处理所有命令。- 发布与订阅功能和其他数据库功能是完全隔离的,前者不写入也不读取数据库,所以 在服务器载入期间,订阅与发布功能仍然可以正常使用,而不必担心对载入数据的完整性产生 影响。
- AOF保存频率通常高于RDB。如果AOF功能打开会优先使用AOF文件还原数据
5.2.4 RDB文件结构

- REDIS
- 文件开头保存REDIS五个字符,表示RDB文件的开始
- RDB-VERSION
- 四字节长
- 记录RDB版本号(目前为0006)
- 因为不同版本的RDB文件不兼容,所以需要根据版本来选择不同的读入方式
- DB-DATA
- 重复多次出现
- 每一个
DB-DATA部分保存着服务器上一个非空数据库的所有数据数据
- SELECT-DB
- 保存着跟在后面的键值对所属的数据库号码
- KEY-VALUE-PAIRS
- 因为空数据库不会被保存到RDB文件,所以这部分至少包含一个键值对的数据
- 键值对数据结构

OPTIONAL-EXPIRE-TIME:记录着过期时间。可选,没有过期时间,该域不出现KEY:键。格式和REDIS_ENCODING_RAW编码的字符串对象一样。TYPE-OF-VALUE:记录VALUE域的值所使用的的编码VALUE:不同类型格式不同
- EOF
- 标志着数据库内容的结尾,值为
rdb.h/EDIS_RDB_OPCODE_EOF
- 标志着数据库内容的结尾,值为
- CHECK-SUM
- 校验和。
uint_64t类型值 - 如果为0,表示Redis关闭了校验和功能
- 校验和。
5.2.5 小结
rdbSave会将数据库数据保存到 RDB 文件,并在保存完成之前阻塞调用者。SAVE命令直接调用rdbSave,阻塞 Redis 主进程;BGSAVE用子进程调用rdbSave, 主进程仍可继续处理命令请求。SAVE执行期间,AOF 写入可以在后台线程进行,BGREWRITEAOF可以在子进程进行,所以这三种操作可以同时进行。- 为了避免产生竞争条件,
BGSAVE执行时,SAVE命令不能执行。 - 为了避免性能问题,
BGSAVE和BGREWRITEAOF不能同时执行。 - 调用
rdbLoad函数载入 RDB 文件时,不能进行任何和数据库相关的操作,不过订阅与 发布方面的命令可以正常执行,因为它们和数据库不相关联。 - RDB 文件的组织方式
- 键值对在 RDB 文件中的组织方式
- RDB 文件使用不同的格式来保存不同类型的值。
5.3 AOF
- RDB将数据库的快照以二进制方式保存到磁盘
- AOF以协议文本方式,将所有对数据库进行过的写入命令(及参数)记录到AOF文件
5.3.1 AOF命令同步
- 同步命令到AOF文件的过程
- 命令传播:Redis将执行完的命令、参数、参数个数等信息发送到AOF程序中
- 缓存追加:AOF程序根据接收到的命令数据,将命令转换为网络通讯协议的格式,然后将协议内容追加到服务器的AOF缓存中
- 文件写入和保存:AOF缓存中的内容被写入AOF文件末尾,如果设定的AOF保存条件被满足的话,
fsync函数或者fdatasync函数会被调用,将写入的内容真正地保存到磁盘中。
5.3.2 命令传播
5.3.3 缓存追加
- 协议文本生成之后,会被追加到
redis.h/redisServer结构的aof_buf末尾 aof_buf保存着所有等待写入AOF文件的协议文本- 缓存追加步骤
- 接受命令、命令的参数、参数个数、所使用的数据库等信息
- 将命令还原成Redis网络通讯协议
- 将协议文本追加到
aof_buf末尾
5.3.4 文件写入和保存
- 每当服务器常规任务函数被执行或者时间处理器被执行时,
aof.c/flushAppendOnlyFile函数都会被调用,进行:WRITE:根据条件,将aof_buf中的缓存写入到AOF文件SAVE:根据条件,调用fsync、fdatastnc函数,将AOF文件保存到磁盘中
5.3.5 AOF保存模式
Redis目前支持三种AOF保存模式:
AOF_FSYNC_NO:不保存AOF_FSYNC_EVERYSEC:每秒保存AOF_FSYNC_ALWAYS:每次执行命令保存
不保存
- 每次调用
flushAppendOnlyFile函数,WRITE都会被执行,SAVE会被略过 SAVE只会在一下任意一种情况下被执行- Redis被关闭
- AOF功能被关闭
- 系统的写缓存被刷新(缓存满,或者定期保存操作)
- 每次调用
每秒保存
- 每次调用
flushAppendOnlyFile,有四种情况:- 子进程正在执行
SAVE- 这个
SAVE的执行时间未超过2秒,程序直接返回,并不执行WRITE或新的SAVE - 这个
SAVE已经执行超过2秒,那么程序执行WRITE但不执行SAVE,此时的WRITE必须等待子线程先完成SAVE
- 这个
- 子进程没有执行
SAVE- 上次成功执行
SAVE距今不超过1秒,那么程序执行WRITE不执行SAVE - 上次成功执行
SAVE距今超过1秒,那么程序执行WRITE和SAVE
- 上次成功执行
- 子进程正在执行
- 每次调用
每次执行命令保存
- 每次执行一个命令后,
WRITE和SAVE都会被执行 SAVE是由Redis主进程执行,所以SAVE执行期间,主进程会被阻塞
- 每次执行一个命令后,
5.3.6 AOF保存模式对性能和安全的影响
- 对主进程的阻塞
不保存:写入和保存都是由主进程执行,阻塞主进程每秒保存:写入由主进程执行,阻塞主进程。保存由子线程执行,不阻塞,但保存操作完成的快嘛会影响写入操作的阻塞时长每次执行命令保存:类似不保存
- 安全性
- 模式1最差
- 模式2兼顾性能和安全性
- 模式3安全性最高,性能最差

5.3.7 AOF文件的读取和数据还原
- 根据AOF文件里的协议,重新执行一遍里面指示的所有命令
- 读取AOF文件并还原步骤:
- 创建一个不带网络连接的伪客户端
- 读取AOF所保存文本,还原出命令、参数、参数个数
- 使用伪客户端完执行命令
- 执行2、3,直到AOF所有命令被执行完毕
- 为了避免对数据的完整性产生影响,在服务器载入数据的过程中,只有和数据库无关 的订阅与发布功能可以正常使用,其他命令一律返回错误。
5.3.8 AOF重写
- 为了解决AOF越来越大的问题
- 创建一个新的AOF文件来代替原有的AOF文件,新AOF文件和原有AOF文件保存的数据库状态完全一样,但新的AOF文件的体积小于等于原有AOF文件的体积
5.3.9 AOF重写的实现
- AOF重写并不需要对原有的AOF文件进行任何写入和读取,它针对的是数据库中键的当前值
- 根据键的类型,使用适当的写入命令来重现键的当前值
5.3.10 AOF后台重写
好处
- 不阻塞主进程
- 子进程带有主进程的数据副本,使用子进程而不是线程,可以在避免锁的情况下,保证数据的安全性
子进程重写期间,主进程还需要继续处理,造成数据不一致
- Redis增加了AOF重写缓存,这个缓存在
fork出子进程之后启用 - Redis主进程在接到新的写命令后,除了将这个写命令追加到现有的AOF文件,还会追加到这个缓存中
- 保证AOF功能继续,即使停机也不会丢失数据
- 所有对数据库的修改都会被记录到AOF重写缓存中
- Redis增加了AOF重写缓存,这个缓存在
子进程完成AOF重写后,向父进程发送一个完成信号,父进程:
- 将AOF重写缓存中的内容全部写入新的AOF文件
- 对新的AOF文件改名,覆盖原有的AOF文件
以上是AOF后台重写,也即是
BGREWRITEAOF命令的工作原理
5.3.11 AOF后台重写的出发条件
- 通过调用
BGREWRITEAOF手动触发 - 服务器在AOF开启后会维持三个变量
- 记录当前AOF文件大小的变量
aof_current_size - 记录最后一次AOF重写后的AOF文件大小
aof_rewirte_base_size - 增长百分比
aof_rewirte_perc
- 记录当前AOF文件大小的变量
- 每次
serverCron函数执行时,检查以下条件是否全部满足,是的话,会触发自动的AOF重写:- 没有
BGSAVE命令在执行 - 没有
BGREWRITEAOF在执行 - 当前AOF文件大小大于
server.aof_rewrite_min_size(默认1MB) - 当前AOF文件大小和最后一次AOF重写后的大小之前比率大于等于指定的增长百分比(默认100%)
- 没有
5.3.12 小结
- AOF文件通过保存所有修改数据库的命令来记录数据库的状态
- AOF文件的所有保存命令都以Redis通讯协议的格式保存
- 不同的AOF保存模式对数据的安全性、已经Redis的性能有很大的影响
- AOF重写的目的是用更小的体积保存AOF文件,整个重写过程基本上不影响Redis主进程处理命令请求
- AOF重写的实际重写工作是针对数据库的当前值来进行的,程序既不读写也不使用原有的AOF文件
- AOF可以手动触发或自动触发
5.4 事件
- 事件是Redis的核心,处理两项重要的任务:
- 处理文件事件:在多个客户端中实现多路复用,接受它们发来的命令请求,并将命令的执行结果返回给客户端
- 时间事件:实现服务器常规操作(
server cron job)
5.4.1 文件事件
- Redis通过在多个客户端之间进行多路复用,从而实现高效的命令请求处理
- 多个客户端通过套接字连接Redis服务器,但只有在套接字可以无阻塞地进行读或者写时,服务器才会和这些客户端进行交互
- Redis将这些因为套接字进行多路复用而产生的事件称为文件事件(
file event),文件事件可以分为读事件和写事件两类
- 读事件
- 读事件标志着客户端命令请求的发送状态
- 当一个新客户端连接到服务器时,服务器会给该客户端绑定读事件,直到客户端断开连接之后,这个读事件才会被移除
- 读事件在整个网络连接的生命期内,都会在等待和就绪两种状态直接切换
- 当客户端连接到服务器,但并没有向服务器发送命令时,读事件处于等待状态
- 客户端发送命令,并且请求已到达(套接字可以无阻塞地执行读操作),读事件处于就绪状态
- 写事件
- 写事件标志着客户端对命令结果的接受状态
- 客户端自始至终都关联着读事件。服务端只会在有命令结果需要传回给客户端时,才会为客户端关联写事件
- 写事件会在两种状态之间切换:
- 当服务器有结果需要返回给客户端时,但客户端还未能执行无阻塞写,那么写事件处于等待状态
- 当服务器有结果需要返回给客户端时,并且客户端可以无阻塞写,那么写事件处于就绪状态
5.4.2 时间事件
- 事件事件记录着那些要在指定时间点运行的时间
- 多个时间事件以无序链表的形式保存在服务器状态中
- 每个时间事件主要由三个属性组成:
when:以毫秒格式的UNIX时间戳为单位,记录执行的时间timeProc:时间处理函数next:指向下一个时间事件,形成链表
- 根据
timeProc函数的返回值,可以将时间事件划分为两类:- 返回
ae.h/AE_NOMORE,该事件为单词执行事件:处理一次后被删除,不再执行 - 如果返回非
AE_NOMORE的整数,为循环执行事件:根据返回值更新when属性,一直更新运行下去
- 返回
5.4.3 时间事件应用实例:服务器常规操作
- 服务器定期自检,这类操作成为常规操作(
cron job) - 由
redis.c/serverCron实现,包括:- 更新服务器各类统计时间,比如时间、内存占用、数据库占用情况等
- 清理数据库中的过期键值对
- 对不合理的数据库进行大小调整
- 关闭和清理链接失效的客户端
- 尝试进行AOF或RDB持久化操作
- 如果服务器时主节点的话,对附属节点进行定期同步
- 如果处于集群模式的话,对集群进行定期同步和链接测试
- Redis将
serverCron作为时间事件来运行,循环执行
5.4.4 事件的执行与调度
- Redis中两种时间呈合作关系:
- 一种事件等待另一种事件执行完毕之后,才开始执行,事件之间不会出现抢占
- 时间处理器先处理文件事件(命令请求),在执行时间事件(调用
serverCron) - 文件时间的等待时间(类
poll函数的最大阻塞时间),由距离到达时间最短的时间事件决定
5.4.5 小结
- Redis事件分为时间事件和文件事件
- 文件时间分读事件和写事件:读事件实现命令请求的接收,写事件实现了命令结果的返回
- 时间时间分为单词执行事件和循环执行时间,服务器常规操作
serverCron就是循环事件 - 文件事件和时间事件之间是合作关系:一种事件会等待另一种事件完成后在执行,不会出现抢占情况
- 时间事件的实际执行时间通常比预定时间晚一些
5.5 服务器与客户端
5.5.1 初始化服务器
- 初始化过程:
- 初始化服务器全局状态
- 载入配置文件
- 创建
daemon进程 - 初始化服务器功能模块
- 载入数据
- 开始时间循环
- 初始化服务器全局状态
redis.h/redisServer记录了和服务器相关的所有数据
- 载入配置文件
- Redis在初始完
server变量之后,会读入配置文件和选项,根据这些配置来对server变量的属性值做相应的修改
- Redis在初始完
- 创建
daemon进程- Redis默认以
daemon进程方式运行,并创建相应的pid文件
- Redis默认以
- 初始化服务器功能模块
- 为
server变量的数据结构子属性分配内存 - 初始化这些数据结构
- 为
- 载入数据
- 将RDB或AOF数据载入到服务器进程。AOF优先被使用
- 开始时间循环
5.5.2 客户端连接到服务器
当服务器完成初始化之后,就准备好接受客户端连接
客户端通过套接字函数
connect到服务器,步骤:- 服务器通过文件事件无阻塞地
accept客户端连接,并返回一个套接字描述符fd - 服务器为
fd创建一个对应的redis.h/redisClient结构实例,并将该实例加入到服务器的已连接客户端链表中 - 服务器在事件处理器为该
fd关联读文件请求
- 服务器通过文件事件无阻塞地
Redis以多路复用的方式来处理多个客户端,为每个已连接客户端维持一个
redisClient结构:- 套接字描述符
- 客户端正在使用的数据库指针和数据库号码
- 客户端的查询缓存和回复缓存
- 一个指向命令函数的指针,以及字符串形式的命令、命令参数、命令个数
- 客户端状态:
SLAVE、MONITOR、事务状态 - 实现事务功能(
MULTI、WATCH)所需的数据结构 - 实现阻塞功能(
BLPOP、BRPOPLPUSH)所需的数据结构 - 实现订阅与发布功能(
PUBLISH、SUBSCRIBE)所需的数据结构 - 统计数据和选项:客户端创建时间,和服务端最后交互时间,缓存大小等
5.5.3 命令的请求、处理和结果返回
- 客户端连上服务器之后,客户端就可以向服务器发送命令请求了
- 服务器处理客户端请求过程:
- 客户端通过套接字向服务器传送命令协议数据
- 服务器通过读事件来传入数据,并将数据保存在客户端对应的
redisClient结构的查询缓存 - 根据客户端查询缓存中的内容,程序从命令表中查找响应命令的实现函数
- 程序执行实现函数,修改服务器的全局状态
server变量,并将命令的执行结果保存到客户端redisClient结构的回复缓存,然后为该客户端的fd关联写事件 - 当客户端
fd的写事件就绪时,将回复缓存中的命令结果传回给客户端
5.5.4 命令请求实例:SET的执行过程
5.5.5 小结
- 服务器经过初始化之后,才能开始接受命令
- 服务器初始化可以分为6个步骤
- 服务器为每个已连接的客户端维持一个客户端结构,保存这个客户端的所有状态信息
- 服务器处理客户端请求流程